前からたまに、MySQLを仕事で使ってきたのですが、照合規則については詳しくなかった自分。現在の仕事で、ひらがなでもカタカナ、小文字でも大文字、全角でも半角が検索でヒットするシステムを作ってほしいとのことで少ししらべてみました。
ちなみに、寿司ビール問題(MySQL と寿司ビール問題 – かみぽわーる)というのは聞いたことあったので、ちょっとは問題あるんだろうなと思ったら、MySQL8では解決されているようです(寿司=ビール問題 : MySQL 8.0でのUTF8サポート入門 (MySQL Server Blogより) | Yakst)。
ただし、何やらデフォルトの文字コードだと日本語の照合にいろいろ問題があるとのこと。
参考:MySQL Innovation Day Tokyo で MySQL 8 の文字コードについて話した – @tmtms のメモ
というのも、デフォルトの「utf8mb4_0900_ai_ci」だと、アクセント違いは同じ文字の扱いになり、大文字小文字も同じ文字という扱いになるそうです。これがどういうことかというと、「はは」と検索したのに、「ばば」や「パパ」がヒットするということです。なんじゃそりゃ。
例えば「びょういん」で検索すると、下記のようになります(ID13~18は半角カタカナです)。

なお、このテーブルには「ひ゛ょういん」や「ひ゜よういん」もいれているのですが、それはヒットしませんでした。

ちなみに、like演算子で、「びょう」としても全部ヒットするわけではないらしいです。半角カタカナの「ビョウイン」や「ピヨウイン」などがでてきてないですね。濁点や半濁点は別の扱いなんでしょうか。

そういえば、先ほど紹介したMySQL8の話のページで知ったのですが、「株式会社」=「㍿」となるそうです。面白いですね。
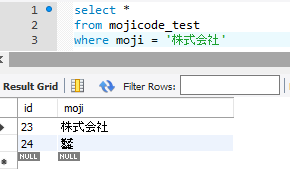
ただ、これもlike演算子だとヒットせず。

内部的にどういう違いがあるんだろう? like演算子だと厳密ってわけでもないみたいだし。
ちなみに、仕事ではいろいろ試した結果、照合順序は「はは」と「ばば」と「ぱぱ」を区別する「utf8mb4_0900_as_ci」を使うことにしました。これだと、ひらがなでもカタカナ、小文字でも大文字、全角でも半角が検索でヒットするので。ただし、「びょういん」=「びよういん」にはなってしまうという。これだけ解決されれば、期待通りだったんだけどなぁ。日本語と英語の大文字小文字の違いを同じような扱いにしないでほしい。

コメント