今月から業務でUiPathを使うようになりました。使ってみると本当、簡単にプログラムを作成できて、もうプログラミングはいらなくなるんじゃないかとさえ思いそうです(注:そんなことはない)。
というわけで、今回はUiPathで簡単にできる、ウェブスクレイピングの機能を紹介。とりあえず、指定のURL(というよりドメイン)内を含むページのすべてのエントリーページを取得したいと思います。UiPathのウェブ操作はIE以外にFirefoxやChromeにも対応していますが、今回は標準で使えるIEで試してみます(FirefoxやChromeは拡張機能を入れる必要がある)。
まず最初に、IEではてブの指定のURLのすべてのページを開いておきます。例えばここのブログだと、http://b.hatena.ne.jp/entrylist?url=http%3A%2F%2Fam-yu.net%2F&sort=eidです。
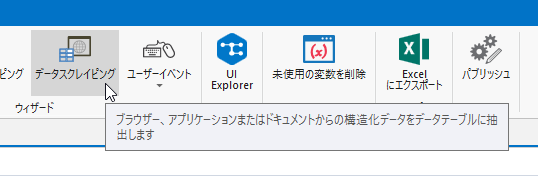
次に、UiPathでプロセスを開始して、リボン上の『データスクレピング』をクリック。
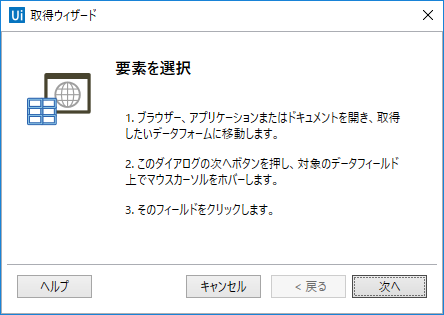
そうすると、下記のような画面が表示されるので、『次へ』をクリック。
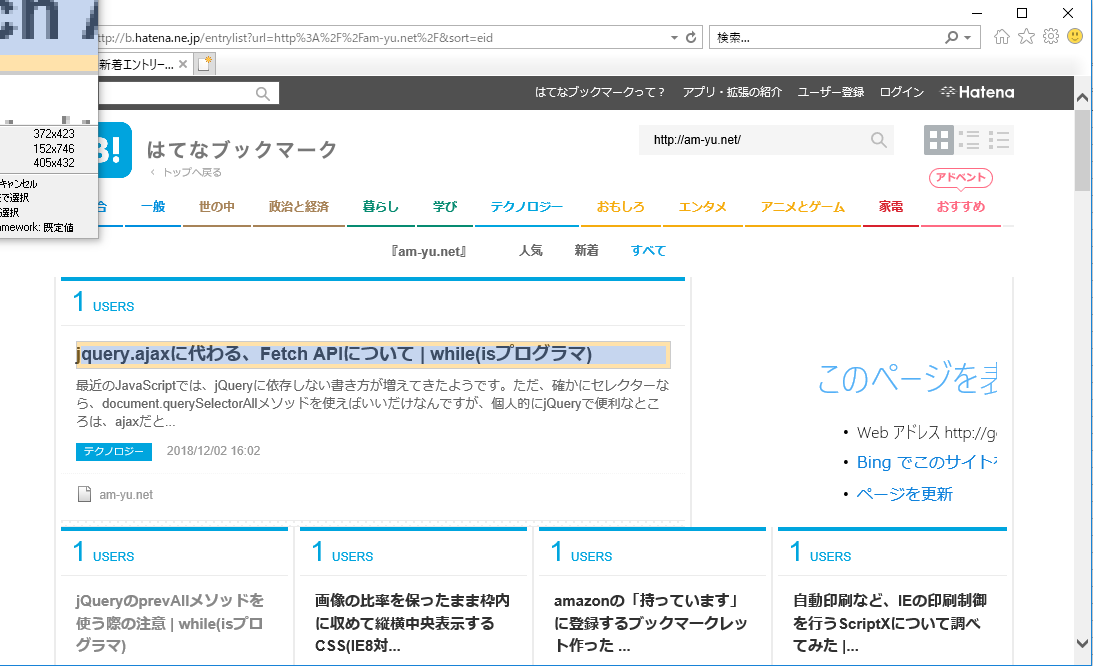
すると、取得したい要素を選択することになるので、取得したい要素を選択します。ここでは、ブクマされているページのタイトルを選択します。
選択すると、下記の画面が表示されます。これは、上記で選択した要素と、同じ種類の要素を選択します。そうすることで、どの要素を取得すればいいかUiPathが自動で判断してくれます。
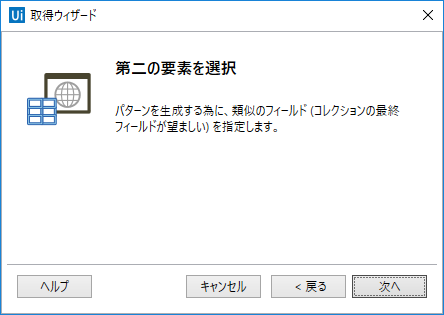
とりあえずここでは、3つ目のタイトル要素を選択することにします。
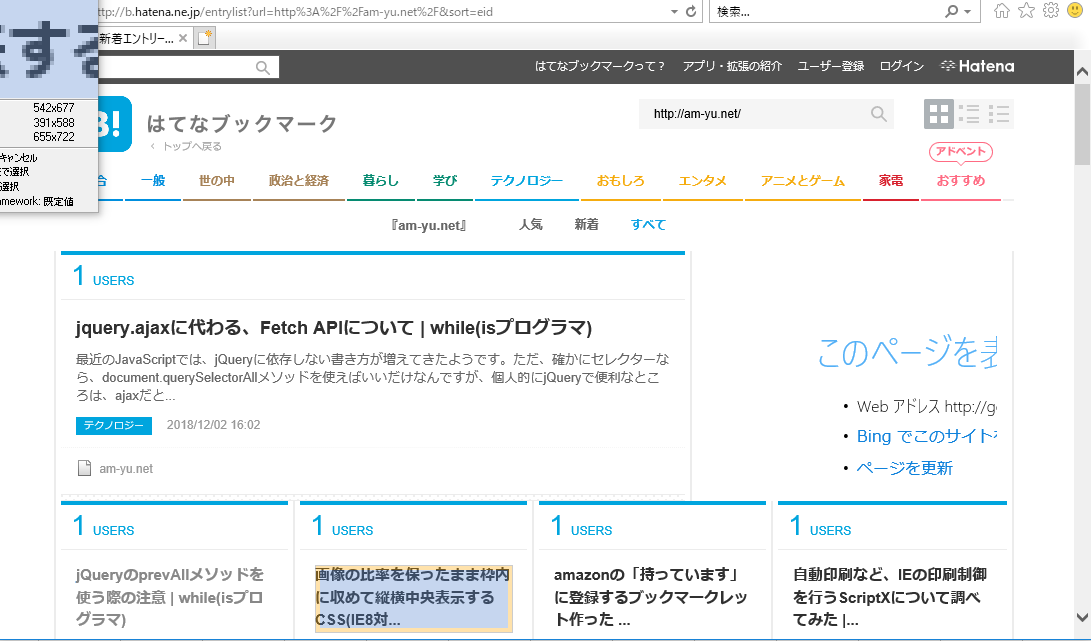
そうすると、『カラムを設定』という画面が表示されるので、テキストカラム名と(指定した要素がリンクであれば)URLカラム名を入力します。とりあえずそのまんまですが、『Title』と『URL』と入力し、『次へ』をクリックします。
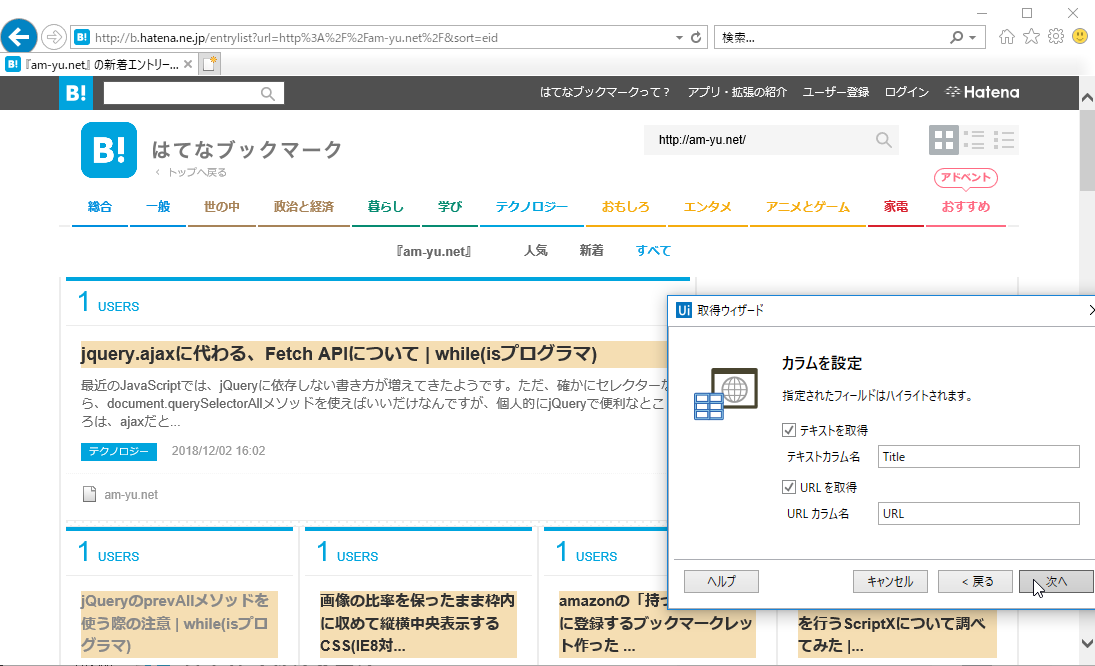
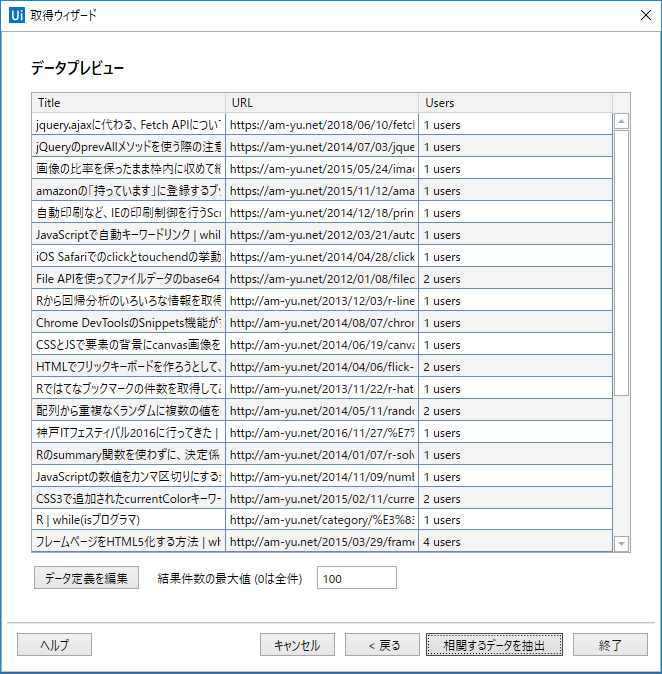
すると、データプレビュー画面が表示されます。こんな感じで取得することになるようです。うまく取得できていそうですね。結果件数の最大値はデフォルトで100と入っていますが、もっと大きくすることもできます(あまり大きくしたり、0とすると最悪、時間がかなりかかってパソコンにもはてブのサーバーにも負荷がかかりそうなのでやめておいたほうがいいです)。とりあえず、100のままにしておきます。ここで終わってもいいのですが、次に『相関するデータを抽出』をクリックします。
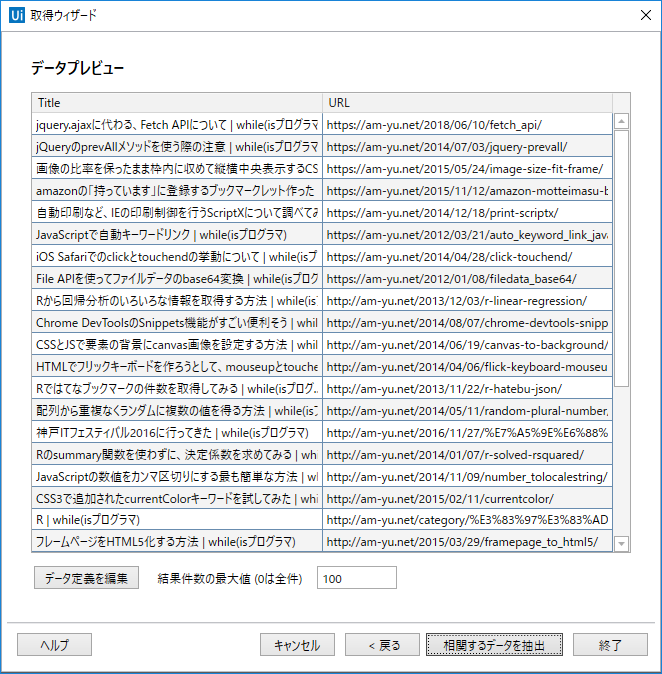
先ほどと同じく要素選択画面となるので、ブクマ数の要素を選択します。
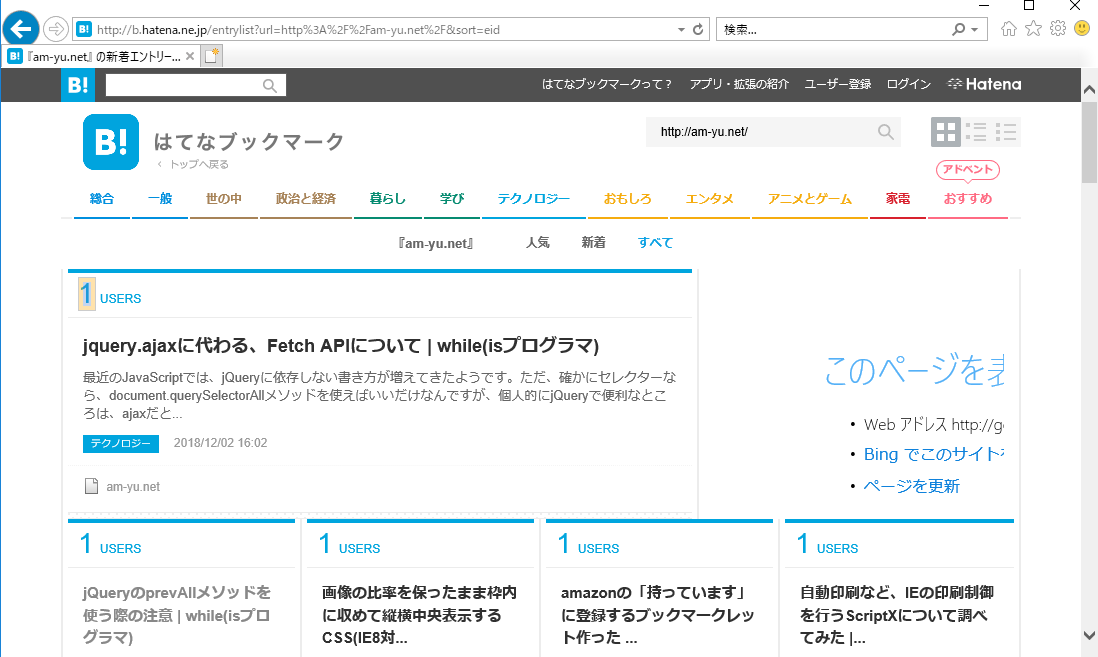
つづいて、タイトルを選択したときと同じように、別のブクマ数の要素を選択します。
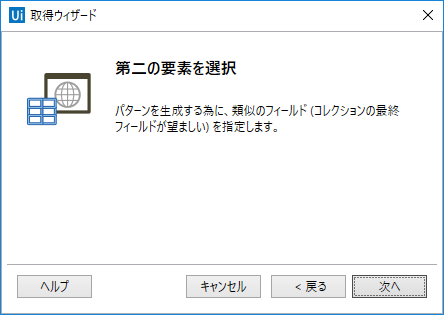
テキストカラム名『Users』としておきます。今回URLはいらないので、チェックは外しておきます。
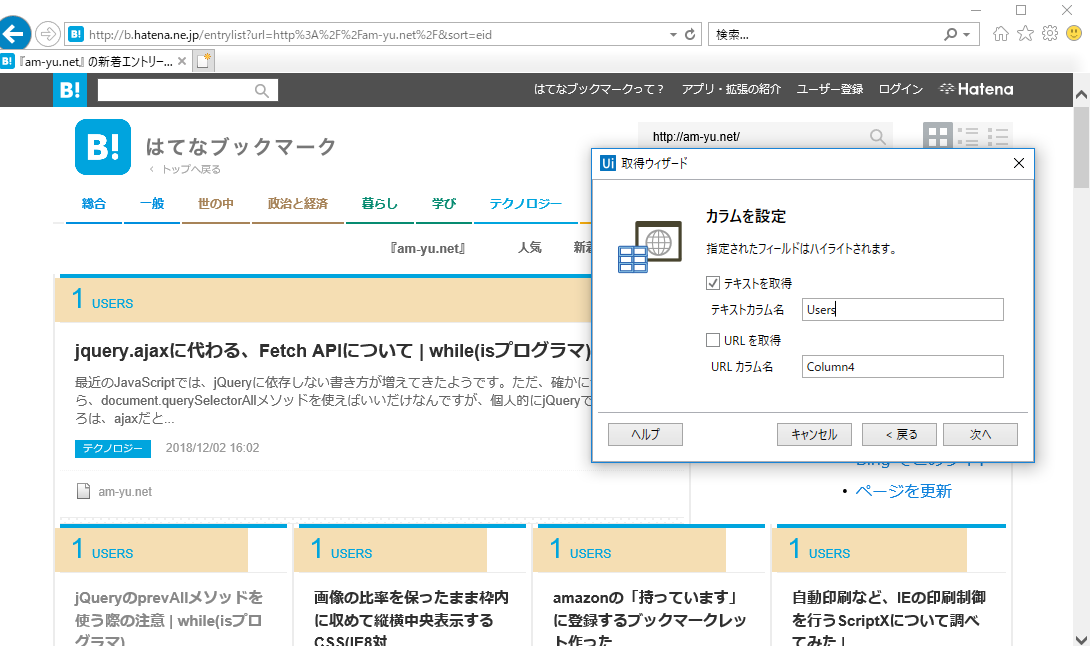
『データプレビュー』は下記のようになりました。ブクマ数もうまく取得できているようです(と言いたいところですが、選択したのはブクマ数の数値部分だけなはずなんですよね。なんで「users」まで取得対象になってしまうのかと……)。とりあえず、「終了」ボタンをクリックします。
そうすると、「データは複数ページにわたりますか?」というダイアログが表示されます。複数ページにまたがるので、「はい」をクリックします。

つづいて、次のページへ遷移するリンク要素をクリックします。この時、マウスのホイールが使えないのですが、キーボードのPage Downキーや矢印キーを使ってページを下まで移動し、「次のページ」の要素を選択します。
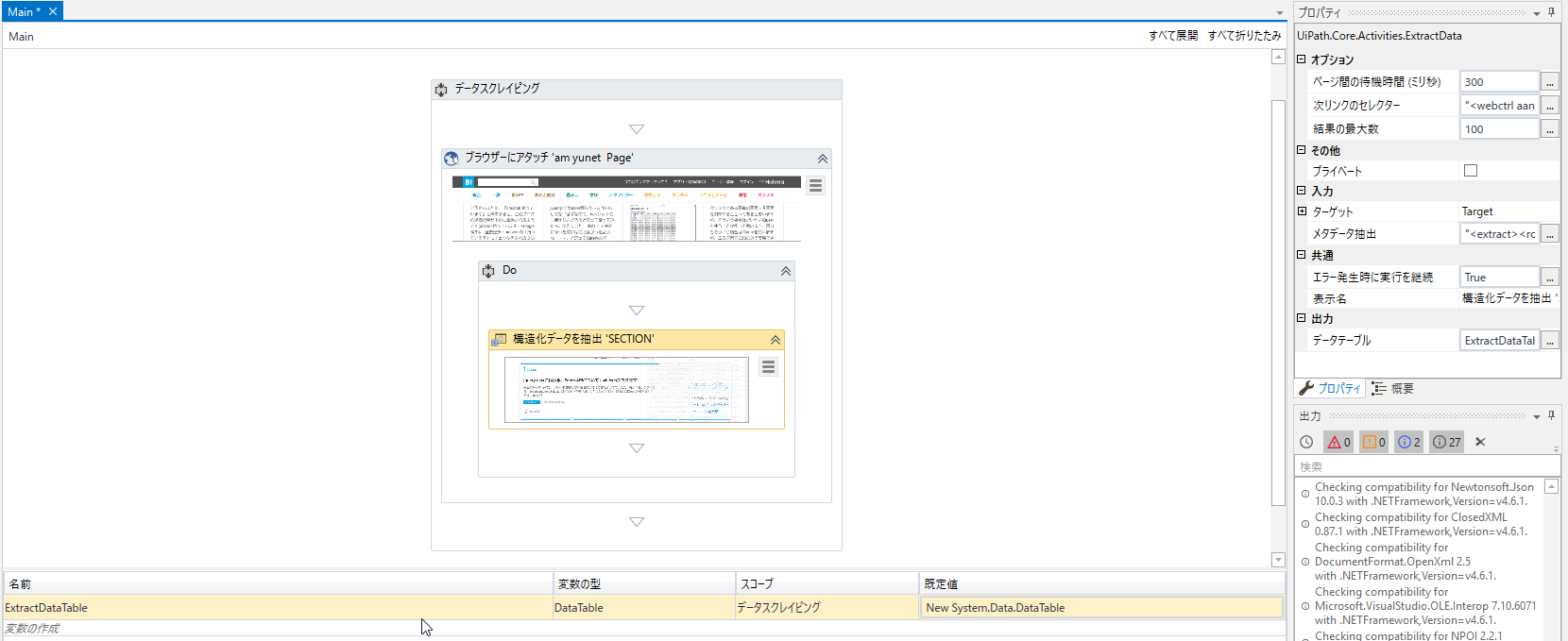
そうすると、UiPath Studioの画面にもどり、データスクレイピングというシーケンスアクティビティや構造化データを抽出用のアクティビティがセットされます。この構造化データを抽出用のアクティビティは出力として、.NetプログラミングではおなじみのDataTableという表形式の型の変数に入ることになります。デフォルトでは「ExtractDataTable」という名前の変数に格納されます。
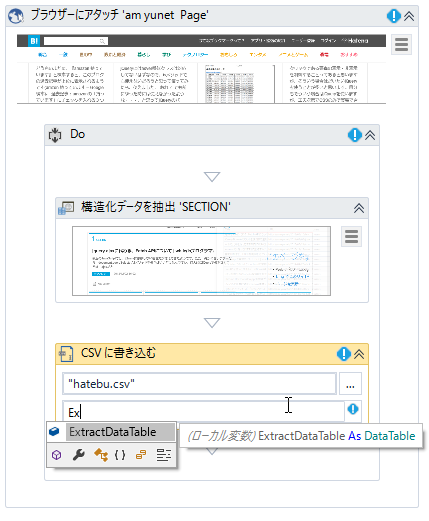
上記で作成したデータテーブルをCSVファイルに保存することにします。CSVに書き込むアクティビティを構造化データを抽出アクティビティの下に置き、ファイル名とデータテーブル変数を入力します。
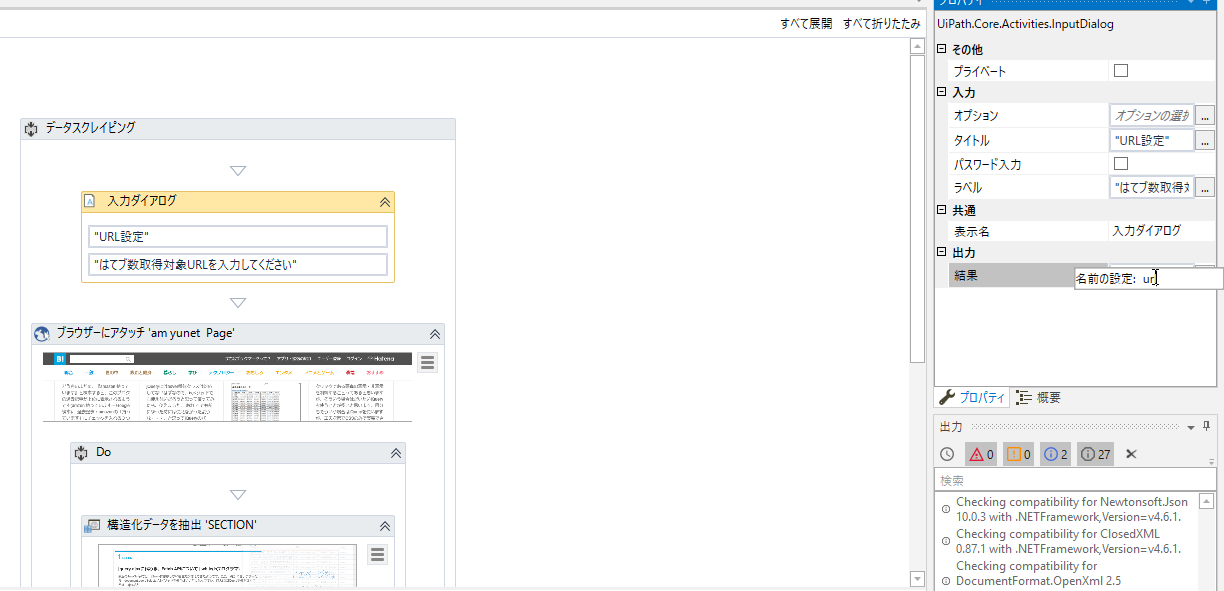
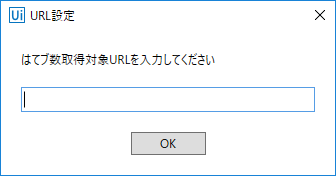
ついでに、ブクマ数を取得するURLは最初に指定できるようにします。入力ダイアログアクティビティを一番上に追加します。出力にはurlという変数を設定することにします。出力結果にカーソルを置き、Ctrl+Kを押すと、自動的に入力して変数が作成されます。
上記で指定したURL用のはてぶページを開くために、ブラウザーを開くアクティビティをセットして、URLを「”http://b.hatena.ne.jp/entrylist?url=” & url & “&sort=eid”」とします(余談ですが、UiPathのマニュアルでは文字列結合に+を使っていることが多いのですが、個人的にはVBの文字列結合は&を使いたい派なので&としています)。処理はこの中のDo(シーケンスアクティビティ)内で行うほうがいいので、先ほど自動的に作成されたブラウザーにアタッチというアクティビティ内のアクティビティをドラッグアンドドロップで移動します。Ctrlキーを押しながら複数のアクティビティを選択することで、複数選択できます(順番がおかしくない? と突っ込まれそうですが、自分も思いました。スクリーンキャプチャを取り直すのが面倒なのでそのままにしています)。
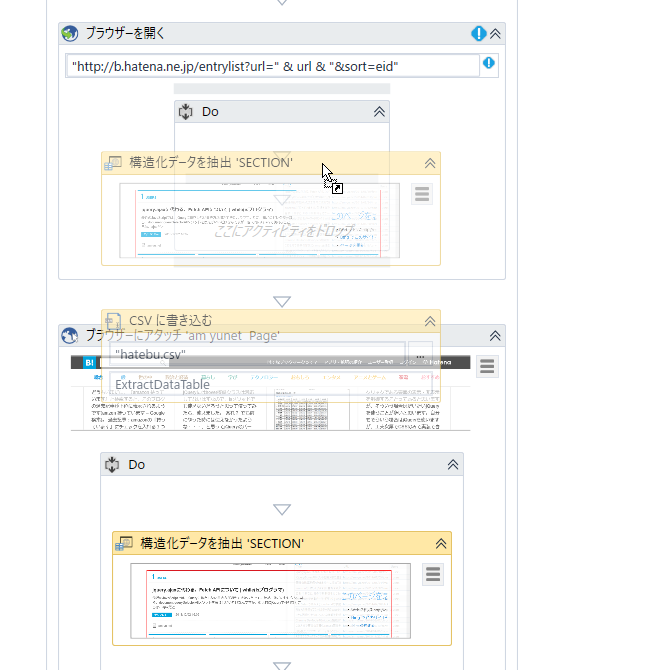
これで完成! と言いたいところなのですが、どうやら青いひし形マークがついています。これがあるということは何かしら失敗しているということです。マウスをあててメッセージを表示してみると、「演算子’&’は型’String’および’UiPath.Core.GenericValue’に対して定義されていません。」とあります。どうやら、先ほど自動的に作成したurlという変数の型は「UiPath.Core.GenericValue」という型になっているようです。この型はジェネリック型変数といって、どんな型もとりうる型となっています(参考:ジェネリック型変数)。なので、変数の型を「String」に変えるとエラーメッセージはなくなります(他に、ブラウザーを開くURLを「”http://b.hatena.ne.jp/entrylist?url=” & url.ToString() & “&sort=eid”」としてもOKです)。

実際にできた、ワークフローは下記のようになりました。
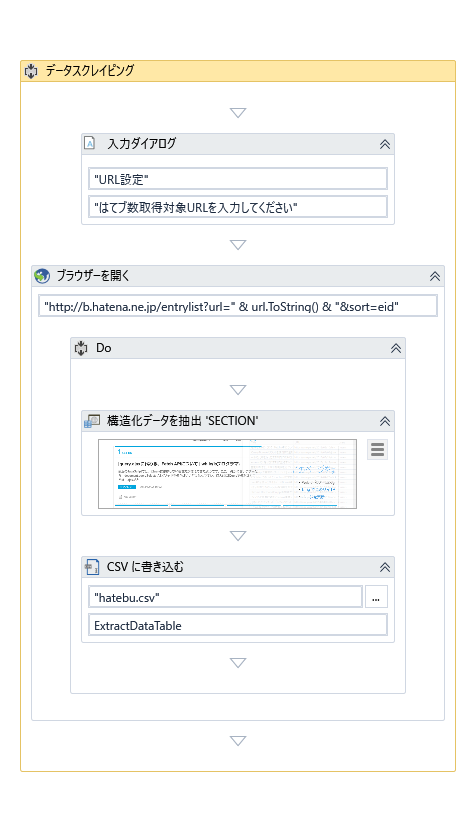
この状態で、実行ボタンを押すとちゃんと動きました。
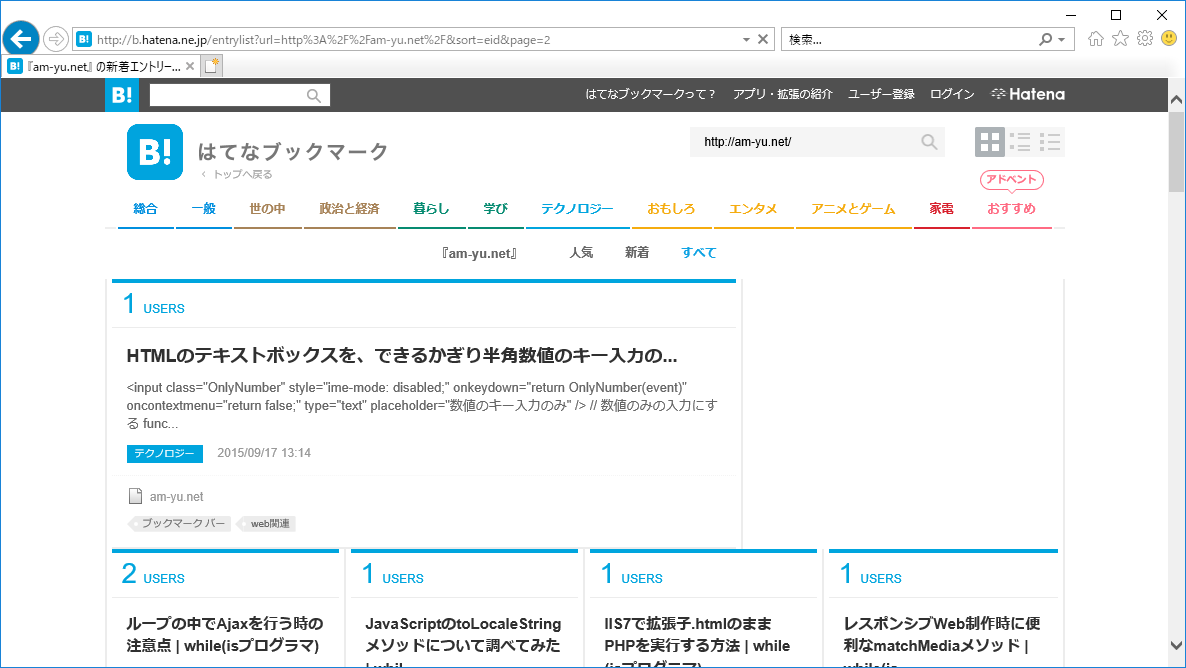
実行するとIEではてブの新着エントリーページが開き、勝手にページが遷移します(ただ、「am-yu.net」で試すと、最後の3ページ目でしばらく止まりました。どうやら、件数が100件未満しかないので、次のページにいきたいのにそのリンク要素がないのでタイムアウトエラーになるまで止まっていたっぽいです)。
処理が終了して、フォルダを確認すると、確かにCSVが作成されていました。
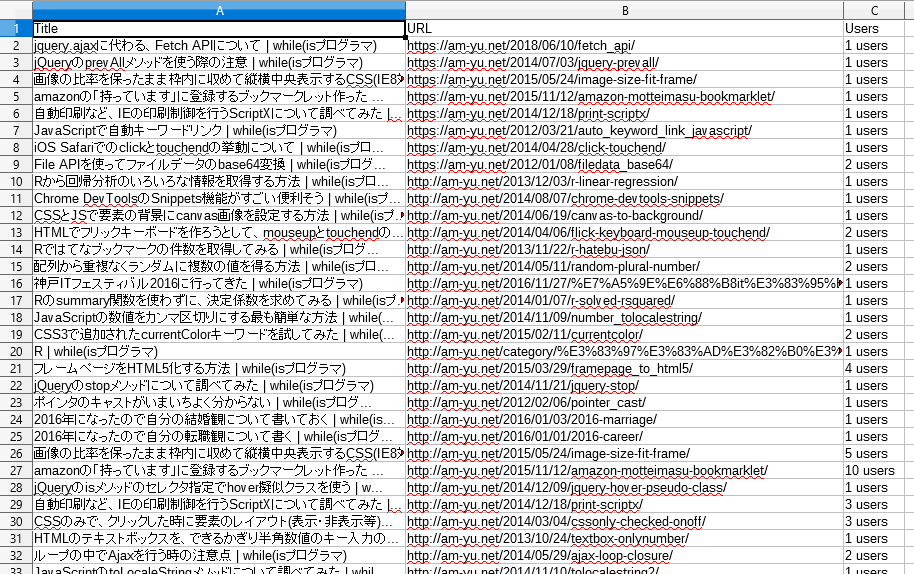
中を見てみると、うまく取得できたようです。
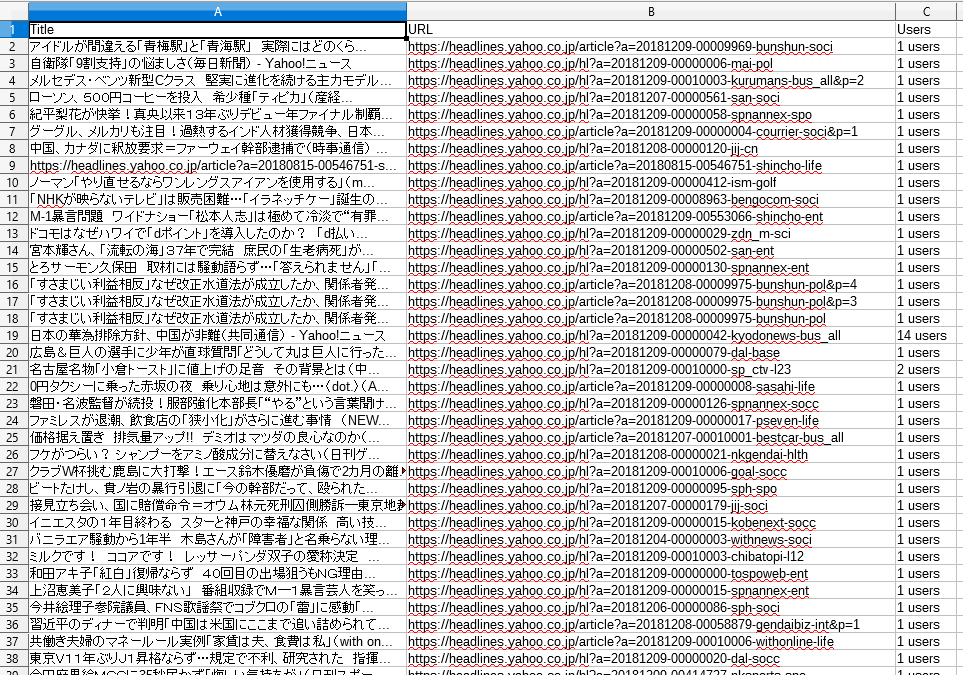
ついでに、Yahoo!ニュースのヘッドラインページで試してみても、うまくいくことを確認しました。
ということで、UiPathだと簡単にウェブスクレイピングを実現できます(取得対象がどういう構造になっているかによりますが)。今後は簡単なウェブスクレイピングについては、UiPathでやってみようと思います。

コメント