SQLで集計する時に、ある特定の値があるグループのみ抽出したいということがあると思います。先日、仕事でそういうことをしたいということがあったのですが、すぐには思いつかず、仕事を終えた後に思いついたので、紹介したいと思います。
今回、使うのは下記のようなサンプルテーブル。テーブル名はtest1で、フィールドがグループ番号、名前、年齢、点数とします(名前と年齢は今期見てるアニメからとっています)。

ここから、中学生(12~14歳)がいるグループのみのグループ番号と平均点を取得するSQLを取得するには下記のようにすればとれます。
SELECT group_id, AVG(score) FROM test1 GROUP BY group_id HAVING MAX(CASE WHEN age BETWEEN 12 AND 14 THEN 1 ELSE 0 END) = 1 ORDER BY group_id
上記の結果が下記です。
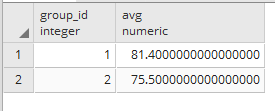
確かに、グループに中学生のいる1と2のみの平均点が表示されました。
上記のSQLは何をしているかというと、まずはGROUP BYで全データを集計し、HAVINGで12~14歳の年齢がいるグループのみに絞っています。
なぜ、これで絞れるかというと、CASEの条件(ここでは「age BETWEEN 12 AND 14」)に一致した値があれば1という値が含まれ、無ければ0しかないということになるからです。それぞれの行にCASE文の結果を付与すると下記のようになります。
SELECT *, CASE WHEN age BETWEEN 12 AND 14 THEN 1 ELSE 0 END FROM test1
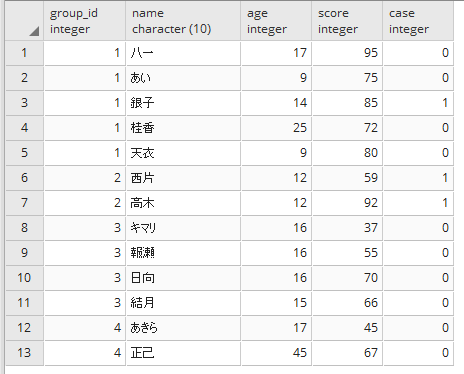
そこからMAX関数で最大値をとってくるので1が含まれていれば1、1が含まれていなければ0となるので、1に等しい値を抽出した結果、条件に一致したグループのみを取得できることになります。
逆に、特定のデータが入っていないもののみを抽出したいという場合は、「= 1」の箇所を「<> 1」とするか、「= 0」とすることで、取得することができます。
なお、HAVINGを使わなくても、サブクエリーを使うことで同じことができます。
SELECT group_id, avg FROM ( SELECT group_id, AVG(score) AS avg, MAX(CASE WHEN age BETWEEN 12 AND 14 THEN 1 ELSE 0 END) AS flg FROM test1 GROUP BY group_id ) AS table1 WHERE flg = 1 ORDER BY group_id
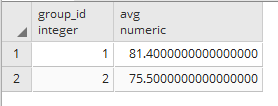
ただ、HAVINGを使ったほうがシンプルなので、基本的にはHAVINGを使ったほうがいいと思います(実行計画のコストも、HAVINGを使ったほうが少しだけ低いようです)。
HAVINGは今までほとんど使ってこなかったのですが、使い始めると結構便利なことに気づきました。いろいろ応用もできそうなので、使いこなしていきたいです。
2018/03/26追記:そういえば、この記事を書こうと最初に思ったときは、条件は中学生以下、つまり「MAX(CASE WHEN age <= 14 THEN 1 ELSE 0 END) = 1」にしようとしていました。ただ、これだと、「MIN(age) <= 14」でもいいことに気づき、中学生が含まれるかどうかという条件に変更しました。こういう条件は、シンプルに考えられるようになりたいです。

コメント